Anomaly Detection : Overview
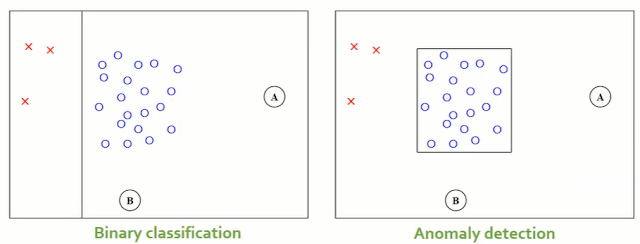
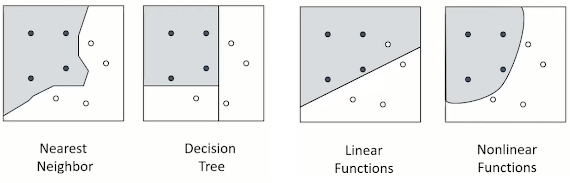
03_1 : Anomaly Detection : Overview 이번에 알아볼 Anomaly Detection은 Data를 기반으로 다른 패턴, 특성을 보이는 객체를 찾아내는 방법이다. 이에 앞서 앞에서 지금까지 공부했던 Machine learning을 지도학습과 비지도학습으로 분류해보자. Machine Learning 정의된 task T 가 있고, 성능을 측정할 수 있는 방법 P 가 있을 때 경험(Data) E 로부터 성능이 향상되는 컴퓨터 프로그램을 학습(Learn) 한다고 지칭한다. Machine Learning 은 이러한 조건을 만족한다. Machine learnnig은 주어진 Data의 특징에 따라 크게 두가지로 분류한다. Supervised learning 주어진 Data에 Target value (Y)를 알고있다. 주어진 Data (X, Y)를 사용하여, X와 Y사이의 관계, 이를 표현 가능한 함수 $Y=f(X)$를 알아내는 것이 목표이다. 지금까지 공부했던 Classification, Regression등이 여기에 해당한다. Unsupervised learning 주어진 Data에 Target value (Y)가 주어지지 않는다. 하지만 Data (X) 자체가 가지고 있는 특징$f(X)$를 알아내는 것이 목표이다. 주어진 Data (X)를 사용하여, 각각의 객체들의 밀도를 추정하거나, 객체들의 군집을 찾거나 변수들 간의 연관성을 유추한다. Anomaly Detection (이상치 탐지) Anomaly는 두가지 관점에서 정의된다. 데이터 생성 메터니즘 " Observations that deviate so much from other observations as to arouse suspicious that they were generated by a different mechanism (Hawkins, 1980) " 일반적인 데이터와 다른 메커니즘으로 발생한 data를 anomaly라고 한다. 데이터 분포 (밀도) ...