Anomaly Detection : Overview
03_1 : Anomaly Detection : Overview
이번에 알아볼 Anomaly Detection은 Data를 기반으로 다른 패턴, 특성을 보이는 객체를 찾아내는 방법이다. 이에 앞서 앞에서 지금까지 공부했던 Machine learning을 지도학습과 비지도학습으로 분류해보자.
Anomaly detection은 제조 공정 과정에서 불량품이나 기계 고장을 탐지하거나, System Security 분야에서 보안이 위협받는 상황을 판별하는 등 다양한 분야에서 사용된다.
Machine Learning
정의된 task T가 있고, 성능을 측정할 수 있는 방법 P가 있을 때 경험(Data) E로부터 성능이 향상되는 컴퓨터 프로그램을 학습(Learn)한다고 지칭한다. Machine Learning은 이러한 조건을 만족한다. Machine learnnig은 주어진 Data의 특징에 따라 크게 두가지로 분류한다.
- Supervised learning
주어진 Data에 Target value (Y)를 알고있다. 주어진 Data (X, Y)를 사용하여, X와 Y사이의 관계, 이를 표현 가능한 함수 $Y=f(X)$를 알아내는 것이 목표이다. 지금까지 공부했던 Classification, Regression등이 여기에 해당한다.
- Unsupervised learning
주어진 Data에 Target value (Y)가 주어지지 않는다. 하지만 Data (X) 자체가 가지고 있는 특징$f(X)$를 알아내는 것이 목표이다. 주어진 Data (X)를 사용하여, 각각의 객체들의 밀도를 추정하거나, 객체들의 군집을 찾거나 변수들 간의 연관성을 유추한다.
Anomaly Detection (이상치 탐지)
Anomaly는 두가지 관점에서 정의된다.
- 데이터 생성 메터니즘
"Observations that deviate so much from other observations as to arouse suspicious that they were generated by a different mechanism (Hawkins, 1980)"
일반적인 데이터와 다른 메커니즘으로 발생한 data를 anomaly라고 한다.
- 데이터 분포 (밀도)
"Instances that their true probability density is very low (Harmeling et al., 2006)"
Data가 발생할 확률 밀도가 매우 낮은 data를 anomaly라고 한다.
Anomaly라는 용어는 분야에 따라 Novelty, Outlier같은 다른 이름으로도 불린다. 다른 이름으로 불리더라도 실제 동작방식은 유사하다. 여기서 주의할 점은 Noise 라는 용어와 햇갈리지 않아야 한다. Noise는 데이터를 수집하는 과정에서 자연발생적으로 생긴 random한 error이다. 현실의 문제를 해결할 때 noise는 항상 있을 수 밖에 없다. 때문에 항상 data에 내제된 noise의 존재를 가정하고 모델을 구성하여야 한다. 반면 Outlier와 같은 경우에는 특이한 상황에서 발생하는, 일반적인 메커니즘과 다른 방법으로 생성된 객체이다. 이 객체를 찾는것은 Data의 특성을 분석하는데 유용할 수 있다.
- Classification vs. Anomaly Detection
Anomaly detection은 정상 객체들을 알아야 함으로 Supervised learning 방법 중 하나이다. 하지만 실제 동작 방식을 살펴보면 Unsupervised learning 방법 처럼 동작을 수행한다. Binary Classification과 비교해보자.
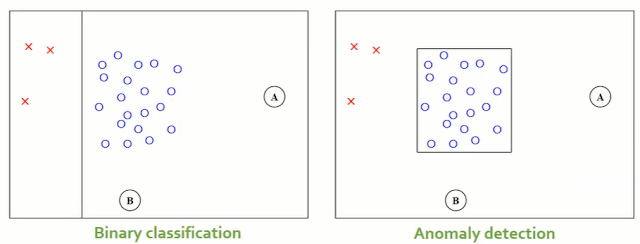
주어진 데이터는 normal(파란색 O)과 abnormal(빨간색 X표)로 구성되어있다. Binary classification인 경우, 두 data를 분류 가능한 분류경계면을 생성할 것이다. 따라서 A, B 객체가 새롭게 입력 되었을 때 normal이라고 분류한다.
반면, Anomaly detection의 경우, abnormal data의 객체 수가 너무 적다는 사실에 주목한다. 너무 적기 때문에 빨간색 3개의 abnormal data만으로 모든 abnormal data를 표현할 수 없다. 따라서 normal data만을 사용하여 normal 의 영역을 만들어낸다. 이 경우 A, B 객체가 새롭게 입력된 경우 normal이 아니다고 판별된다. 이 말은 A, B가 abnormal이라는 말과 다르다. A, B가 불량인 것이 아니라 일단 normal이 아니고, 어떤 범주인지는 분석을 통해 알아보아야 한다.
Anomaly detection의 가장 큰 특징은 Anomaly를 학습하는 것이 아니라 normal의 특징을 학습한다는 점이다. 이를 통해서 새로운 input이 주어졌을 때 normal인지 아닌지를 판별한다. 때문에 supervised learning이지만, 여러 범주 data를 다 사용하지 않고 normal의 정보만을 사용함으로 unsupervised learning과 유사하게 동작한다고 말한 것이다.
- Generalization vs. Specialization
Anomaly detection을 할 때 Generalization(일반화)와 Specialization(구체화, 특수화)간의 trade off를 조절하는 것이 중요하다.

- Assumption
Anomaly detection에서 기본적으로 전제하는 것은 normal data의 수가 abnormal보다 더 많다는 것이다. 이를 기반으로 normal data만을 사용하여 Training을 수행하고, model을 생성한다. Classification과 비교해보면 좀더 명확하다.
<Classification>

<Anomaly detection>

그렇다면 Data가 주어졌을 때 Classification과 Anomaly detection 중 어떤 방법을 사용할지 어떻게 결정할까?

Class imbalance하더라도 sampling과 같은 imbalance를 handling 하는 기법을 사용하여 imbalance를 완화할 수 있다. 하지만 이런 기법들 마저 적용할 수 없을 정도로 소수 범주의 객체가 매우 적은 경우에만 Anomaly detection을 사용하는 것이 좋다. 예를들어 normal이 999,000개, abnormal이 1000개 있는 경우라면, 여러 기법들을 적용하여 Classification을 사용하는 것이 일반적으로 더 좋은 성능을 기대할 수 있다. 하지만 normal이 9990개, abnormal이 10개 있는 경우라면, 10개의 abnormal data만으로 abnormal의 특징을 모두 반영하기 어렵다. 때문에 이런 경우라면 Anomaly detection을 사용하는 것이 일반적으로 더 좋다.
Type of Abnormal data (Outlier)
Abnormal data라고 하더라도 여러 종류로 분류된다.
- Global outlier
"Object that significantly deviates from the rest of the data set."
Global outlier란 대다수의 Data set과 완전히 다른 객체이다. 일반적으로 생각하는 Outlier이다. 이번에 알아볼 Anomaly detection들이 구분하고자 하는 anomaly이다.
- Contextual outlier
"Object that deviates significantly based on a selected context."
Contextual outlier란 상황(context)에 따라서 outlier일수도 아닐수도 있는 객체이다. 예를들어 기온이 30도라는 상황(객체)은 아프리카에서는 outlier가 아니지만, 알레스카에서는 outlier일 것이다.
- Collective outlier
"A subset of data objects collectively deviate significantly from the whole data set, even if the individual data objects may not be outliers."
객체 하나하나는 outlier가 아니더라도, 전체 data를 보았을 때 편차가 심하게 나는 경우, Collective outlier라고 한다. 예를들어 DDos공격을 보았을 때, 한명 한명의 접속 패킷을 정상이지만 한번에 접속이 너무 많이 이루어진다면 서버에 문제가 발생한다. 이 경우가 Collective outlier일 것이다.Challenges
Abnormal detection에서 가장 Challenging 한 고려사항은 아래의 3가지가 있다.
- Modeling normal objects and outliers properly
Normal과 abnormal data 사이의 경계가 매우 모호하다(Gray area). 연속한 데이터에 대하여 어디를 경계로 설정할지 결정하기 어렵다.
- Application-specific outlier detection
Abnormal detection이 어디에 사용될지에 따라서 모델의 구성 방법이 다르다. Application을 고려하여 모델의 distance measure 방법이나, outlier 판정 방법을 설계해야 한다.
예를들어 의료 분야에 사용되는 경우, 작은 오차도 허용하면 안되기 때문에 작은 편차도 outlier가 된다. 반면 마케팅 분야에 사용되는 경우 어느정도 편차이더라도 정상으로 판별할 수 있다.- Understandability
이상치를 판별하였더라도 그 객체가 왜 이상치인지 설명할 수 있어야 한다. 하지만 normal과 abnormal을 명확히 구분하는 설명을 만드는 것은 매우 어렵다.
Performance Measures
Anomaly detection의 Train과정에는 Normal data만 사용하는 unsupervised learning과 유사한 과정이라고 했었다. 그렇다면 supervised learning으로써 abnormal data는 어디에 사용될까? 바로 Performance를 test할 때 사용된다.
- Confusion matrix

Model의 Performance를 test할 때 confusion matrix의 각 값을 계산하고 이를 바탕으로 아래 각 비율을 계산한다.
- Detection Rate
$$(Identified\;as\;abnormal)/(Actually\;abnormal) = A/(A+B)$$
실제 Abnormal 중에서 정상적으로 abnormal이라고 판별된 비율을 나타낸다.
- False Rejection Rate (FRR)
$$(Rejected\;as\;abnormal)/(Actually\;normal) = C/(C+D)$$
실제 Normal 중에서 Abnormal로 판별된 비율을 나타낸다.
- False Acceptance Rate (FAR)
실제 Abnormal 중에서 normal로 판별된 비율을 나타낸다.
FRR과 FAR은 반비례 관계에 있다. 만약 abnormal로 더 많이 판별하는 모델의 경우, FRR은 크지만 FAR은 작을 것이다. 반면 normal로 더 많이 판별하는 모델의 경우, FRR은 작지만 RFA은 클 것이다.
위에서 이야기 했듯이 Anomaly detection에서 큰 어려움 중 하나는 Normal과 abnormal data 사이의 경계가 매우 모호하다는 것이다. 이러한 영역을 Gray area라고도 부른다. 따라서 실제 구현에서는 Normal인지 Abnormal인지 판별한 결과를 반환하지 않고 Normal일 확률과 Abnormal일 확률을 반환한다. 이 결과를 위의 Confusion matrix와 비율식들을 계산하고, Abnormal인지 아닌지를 결정하는 Cut-off 값을 바꿔가면서 ROC curve를 만들 수 있다..

이 결과로 부터 Cut-off에 dependent한 특징을 2가지 계산할 수 있다.
- Equal Error Rate (ERR)
FAR과 FRR 값이 같은 경우의 Error rate이다. 위의 그림에서 빨간색 $y=x$ 그래프와 교점이 ERR 값이다. 이 값은 낮을수록 더 좋은 Performance이다.
- Integrated Error (IE)
AUROC를 계산하듯이 아래 검은색 면적의 넓이이다. 분류 문제에서는 AUROC가 클수록 좋은 Performance이지만 Anomaly detection에서는 IE가 작을수록 좋은 Performance이다.
※ 이 글은 고려대학교 산업경영공학과 강필성 교수님의 IME654 강의를 참고하여 작성되었습니다.



댓글
댓글 쓰기