t-SNE
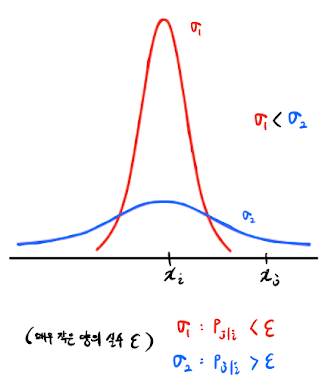
01_7 : Dimensionality Reduction : t-SNE Introduction t-SNE는 최근 가장 많이 사용되는 비선형 차원축소 방법으로써 데이터의 시각화에도 자주 사용된다. t-SNE에 대하여 알아보기에 앞서, 그 기반이 되는 Stochastic Neighbor Embedding(SNE)에 대하여 알아보자. Stochastic Neighbor Embedding (SNE) 이란? non-local distance를 보존하는 것 보다, local distance를 보존하는 것이 더 중요하다. Local distance를 최대한 보존할 수 있도록 새로운 좌표계를 만드는 것이 LLE와 SNE의 목표이다. SNE은 LLE와 유사하지만, neighbor를 선택하는 방법에서 차이점이 있다. LLE가 Deterministic(결정론적인)한 방법을 사용한 반면, SNE는 Stochastic(확률론적인)방법을 사용한다. 기존의 LLE에서는 Deterministic하게 가장 가까운 k개의 neighbor를 선택하여 그 local distance를 보존하도록 하였다. SNE는 LLE와 다르게 Probabilistic하게 neighbor를 선택하고, 각 pairwise local distance를 보존한다. 즉, 각각의 pairwise distance가 local인지 non-local인지 확률적으로 결정한다. SNE에서 하나의 data point가 다른 data point를 neighbor로 선택할 확률을 어떻게 나타내는지 알아보자. $i$라는 data point를 기준으로, high dimension(원본 Data의 차원)과 low dimension(차원 축소한 Data의 차원)으로 나누어 생각해보자. Probability of picking $j$ given in high D 원본 Data (차원 $d$)에서 객체 $i$가 $j$를 이웃으로 선택할 확률 $$p_{j|i} = \frac{e^{-\frac{||x_i-x_j||^2}{2\sig...