Graph-based SSL
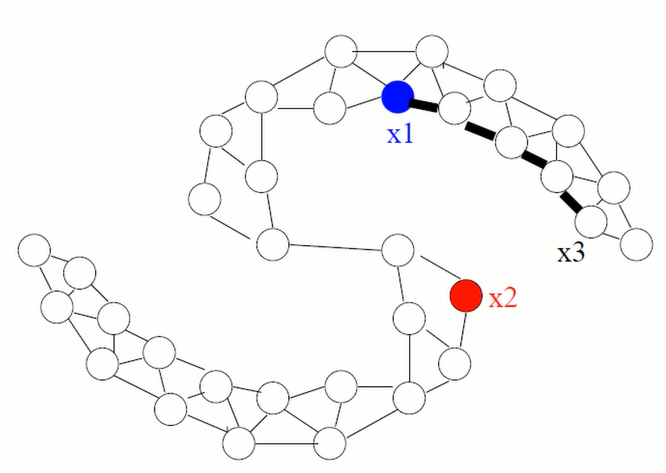
05_3 : Semi-Supervised Learning : Graph-based SSL 이번 글에서는 Graph 기반의 Semi-Supervised Learning을 알아보자. Graph-based SSL 가장 기본적인 아이디어는 우리에게 주어진 Data instance들을 Graph의 Node로 표현하고, 각 Data들의 유사성을 Edge로 표현하는 것이다. 여기서 가정은 아래와 같다. A graph is given on the labeled and unlabeled data Instances connected by heavy edge tend to have the same label 구성된 Graph에 대하여 두 instance가 heavy edge, 강한 연결관계를 갖고있다면 두 Instance가 동일한 label일 가능성이 높다고 간주한다. Graph Construction Nodes : $X_l \cup X_u$ Edges : Similarity weights computed from features, e.g. K-nearest neighbor graph : Unweighted (0 or 1 weights) Fully connected graph, weight decays with distance $$ w_{ij} = exp \big(\frac{-||x_i - x_j ||^2} { \sigma^2 } \big) $$ $\epsilon$-radius graph K-nearest neighbor (KNN) 방법은 가장 가까운 K개를 1 weight로 연결한다. 때문에 data의 밀도를 고려하지 못하는 단점이 있다. Fully connected graph의 경우, 모든 경우를 표현하지만, Graph의 크기가 너무 커진다는 단점이 있다. $\epsilon$-radius graph 방법은, 거리가 일정 Cut-off 이하인 Node들 만을 Edge로 연결한다. 이 경우 data의 밀도를 고려 가능하지만, 모든 instance가 연결된다는 보장이 없다는 단점...