Semi-Supervised Learning : Overview
05_1 : Semi-Supervised Learning : Overview
이번 글에서는 Semi-Supervised Learning 준지도학습이 어떤 것인지, 목적이 무엇인지 알아볼 것이다.
Machine Learning Categories
일반적으로 Machine Learning 방법은 크게 두가지로 분류된다.
- Supervised Learning (지도학습)
모든 Data에 Labeling이 완료되어, 입력 X와 출력 Y를 알고있다. 학습을 통해서 $f(x)=y$를 잘 추정하는 함수 $f$를 찾는 것이 목적이다.
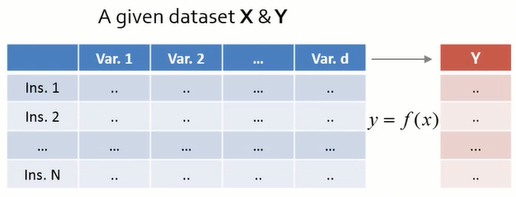
- Unsupervised Learning (비지도학습)
Data의 Labeling이 수행되지 않았고, 입력 X만을 알고있다. 학습을 통해서 data 고유의 특징이나 분포를 찾는 것이 목적이다.


Backgrounds
준지도학습이라는 방법이 만들어진 계기는, Labeling을 하는 것이 매우 비싸고 소모적이기 떄문이다. 일반적으로 Machine Learning에 사용할 데이터는 Row Data인 경우가 많다. 이를 지도학습에 사용하기 위해서 인력과 시간과 돈을 들여 일일이 Labeling을 하는 과정이 필요하다.
의료 data와 같이 Data를 전문가만 이해할 수 있고 labeling이 가능한 경우도 있고, 반도체 공정 data와 같이 최첨단 장비를 사용해 검사를 수행해야 labeling이 가능한 경우도 있다. 중국어 data와 같은 경우 4000문장을 labeling하는 과정에서 4년이 걸렸을 정도이다.
현실 상황에서는 위와 같이 Labeled 된 data를 수집하기 어려운 경우가 많다.
Purpose
준지도학습의 목표는 Labeled data와 Unlabeled data를 모두 사용하여 한 종류의 data만을 사용하는 경우보다 더 좋은 모델을 만드는 것이다.



Semi-supervised Learning (SSL)
그렇다면 모든 Unlabeled data를 준지도학습에 사용할 수 있을까?
그렇지 않다.
준지도학습에 사용하기 위해서 Unlabeled data가 가져야 하는 조건이 있다.
Unlabeled data가 아무런 의미 없이 Random한 분포를 가진다면 우리가 여기서 얻을 수 있는 추가적인 정보는 없다.

반면 아래와 같이 unlabeled data가 군집을 이루고 있다면 어떨까?

위와 같이 Unlabeled data가 가져야 하는 조건을 Cluster(Manifold) Assumption이라고 말하기도 한다.
- Cluster Assumption
- The data from clusters.
- Pointers in the same cluster are likely to be of the same class.
대다수의 현실 data들이 위와 같은 조건을 만족하는 것으로 보여진다.
Cluster(Manifold) Assumption을 만족하는 Unlabeled data를 어떻게 유용하게 사용하는지 1차원 상에서 예시를 들어보자.

Notation
앞으로 사용하게 될 Notation들을 짚고 넘어가자.
- Input instance : $\mathbf{x}$, each label $y$
- Learner : $f$ : $\mathcal{X} \rightarrow \mathcal{Y}$
- Labeled data : $(\mathbf{X}_l,y_l) = \{(\mathbf{x}_{1:l},y_{1:l}\}$
- Unlabeled data : $\mathbf{X}_u = \{(\mathbf{x}_{l+1:n})\}$ (available during training)
- Usually $l \ll n$ : 일반적으로 labeled data보다 unlabeled data가 더 많다.
- Test data : $\mathbf{X}_{test} = \{(\mathbf{x}_{n+1:})\}$ (not available during training)
+addition
보편적으로 Semi-Supervised Learning과 Transductive Learning은 자주 혼용되어 사용된다. 하지만 엄밀히 말해, 두 방법은 목표가 다르다.
- Semi-Supervised Learning
Ultimately applied to the test data (inductive)
SSL의 경우 $\mathbf{X}_u$를 사용하여 $\mathbf{X}_{test}$를 잘 맞추는 것이 목표이다.
- Transductive Learning
Only concerned with the unlabeled data.
Transductive Learning의 경우 현재 주어진 Unlabeled data $\mathbf{X}_u$의 $Y$값을 잘 맞추는 것이 목표이다.
여러 종류의 Learning 방법들을 정리한 도표를 읽어보도록 하자.

※ 이 글은 고려대학교 산업경영공학과 강필성 교수님의 IME654 강의를 정리하고, 공부한 내용을 추가하여 작성되었습니다.



댓글
댓글 쓰기