Neural Network (요약)
1. Artificial Neural Network (인공신경망)
- Overfitting이 문제점이 되어 잘 사용되지 않았었음
- 2000년 초 해당 여러 문제가 해결되면서 많이 사용되기 시작
- Training
- Decide input, output, hidden layer's number of node
- Find weight using training algorithm (Back-propagation algorithm)
2. Back-propagation algorithm
- Input layer에서 멀어질수록 Chain Rule에 의해서 Update되는 Weight의 양이 적어진다.
- Activation function
- 미분 가능한 함수!
- Sigmoid : 미분식 계산이 쉬움 $f^{\partial}(x) = f(x)(1-f(x))$
3. Deep Neural Network
- Multiple hidden layers
- Vanishing gradient problem
- Sigmoid의 미분값은 0~0.25사이의 값
- 여러 layer를 update 하게 되면 계속 작아지는 문제가 발생
- ReLU
- Layer-wise training
- Overfitting
- Collecting more data : consuming and expensive
- Data augmentation
- Dropout $\rightarrow$ Thinner model, ensemble, focus on more features(less idle node)
- Local minima
- Problem even with enough training data
- Start with multiple random points
4. Deep Neural Networks (cont.)
- 기존의 Machine Learning 방법의 경우 사람이 직접 feature를 선택(Hand crafted)하였고, 정보의 손실이 있어서 학습에 어려움이 있었다
- 반면 DNN은 학습을 통해 Data에서 적합한 feature를 추출하여 사용한다
- 유연하고 범용적으로 학습 가능한 프레임워크를 제공하여 다양한 활용이 가능하다
- Supervised / Unsupervised 둘 다 가능
- End-to-End system
- 방대한 training data가 필요하다 (Data가 많아질수록 성능이 좋아진다)
- GPU
- Big Data
- Better learning algorithms
- Fat+Short vs. Thin+Tall
- Fat+Short
- Thin+Tall
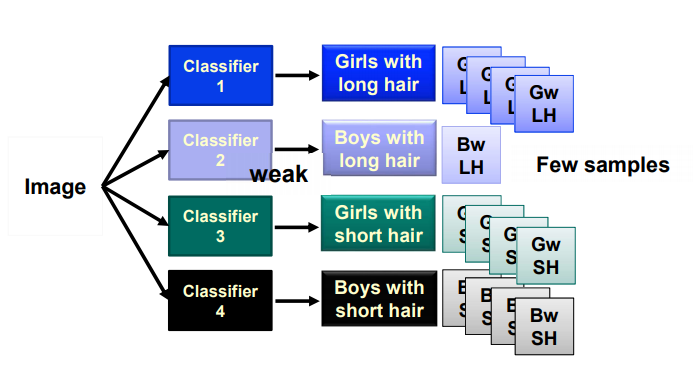
- Deep $\rightarrow$ Modularization
- Modularization을 통해 각기 다른 Classifier를 학습하고 합성하게 된다.
- 때문에 특정 적은 class에 대하여도 잘 작동 가능하게 만든다.

5. Convolutional Neural Network
- Spatial correlation is local
- Use : Locally connected layer & Weight sharing
- Pooling : down sampling
- Filter의 결과로 feature가 각기 다른 위치에서 발생할 수 있다
- Data의 translation 변환에 대하여 robust하게 만들어 준다
- Max-pooling
- Average-pooling
- L2-pooling



댓글
댓글 쓰기